文本检测(Text Detection)是计算机视觉领域的经典问题,该技术旨在寻求一种可靠方法作为文本识别技术的前端,是目标检测(Object Detection)领域的一个子问题
检测(Detection)在计算机视觉中的位置
计算机视觉有四大基本任务: 分割(classification)、定位(检测localization、detection)、语义分割(Semantic segmentation)、实例分割(Instance segmentation) 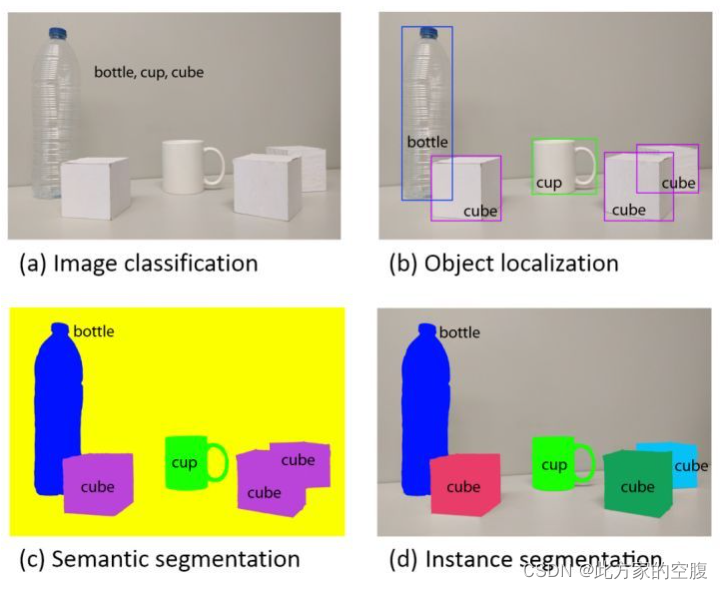
这四个任务需要对图像的理解逐步深入。给定一张输入图像,图像分类任务旨在判断该图像所属类别。定位是在图像分类的基础上,进一步判断图像中的目标具体在图像的什么位置,通常是以包围盒的(bounding box)形式。在目标定位中,通常只有一个或固定数目的目标,而目标检测更一般化,其图像中出现的目标种类和数目都不定。语义分割是目标检测更进阶的任务,目标检测只需要框出每个目标的包围盒,语义分割需要进一步判断图像中哪些像素属于哪个目标。但是,语义分割不区分属于相同类别的不同实例。例如,当图像中有多只猫时,语义分割会将两只猫整体的所有像素预测为“猫”这个类别。与此不同的是,实例分割需要区分出哪些像素属于第一只猫、哪些像素属于第二只猫。此外,目标跟踪通常是用于视频数据,和目标检测有密切的联系,同时要利用帧之间的时序关系。
作者:张皓 链接:https://www.zhihu.com/question/36500536/answer/304469552 来源:知乎
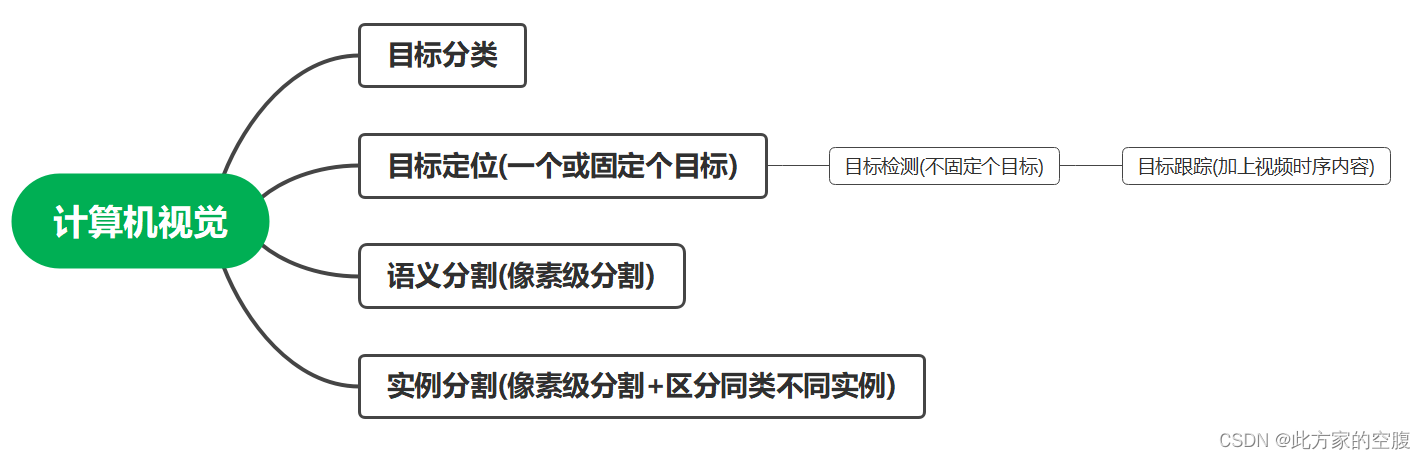
上图中,从上到下逐渐复杂
复杂程度: 分割(同分类)-->定位(一个或固定数目的目标)-->检测(和定位其实很类似,也是用一个bounding box)-->语义分割(像素级的分割)-->实例分割(在前者的基础上区分出同类的不同实例)
检测任务
经典数据集
PASCAL VOC 包含20个类别。通常是用VOC07和VOC12的trainval并集作为训练,用VOC07的测试集作为测试。
MS COCO COCO比VOC更困难。COCO包含80k训练图像、40k验证图像、和20k没有公开标记的测试图像(test-dev),80个类别,平均每张图7.2个目标。通常是用80k训练和35k验证图像的并集作为训练,其余5k图像作为验证,20k测试图像用于线上测试。区别于ImageNet常用于做分类,COCO用来做检测,因为COCO没label
评价指标
mAP (mean average precision) 目标检测中的常用评价指标,计算方法如下。当预测的包围盒和真实包围盒的交并比大于某一阈值(通常为0.5),则认为该预测正确。对每个类别,我们画出它的查准率-查全率(precision-recall)曲线,平均准确率是曲线下的面积。之后再对所有类别的平均准确率求平均,即可得到mAP,其取值为[0, 100%]。
交并比(intersection over union, IoU) 算法预测的包围盒和真实包围盒交集的面积除以这两个包围盒并集的面积,取值为[0, 1]。交并比度量了算法预测的包围盒和真实包围盒的接近程度,交并比越大,两个包围盒的重叠程度越高。
发展历史

经典的LeNet、AlexNet、VGG、GoogleNet用来做分类,RCNN、Fast RCNN、Faster RCNN、YOLO、SSD则用来做检测
单阶段目标检测方法是指只需一次提取特征即可实现目标检测,其速度相比多阶段的算法快,一般精度稍微低一些
two-stage检测算法将检测问题划分为两个阶段,首先产生候选区域(region proposals),然后对候选区域分类(一般还需要对位置精修),这类算法的典型代表是基于region proposal的R-CNN系算法,如R-CNN,SPPNet ,Fast R-CNN,Faster R-CNN,FPN,R-FCN等
几个文本检测的较新方法
FOTS(【2018CVPR】Fast Oriented Text Spotting with a Unified Network)
这篇论文是一个集合了文本检测跟文字识别两部分的一个统一的端到端的框架,可同时对图像中的文字进行检测跟识别。
之前的大部分方法都是将检测跟识别当做两个独立的任务去做,先检测,再识别。这篇论文提出的框架处处是可微的,所以可以对其进行端到端的训练,结果表明,该网络无需复杂的后处理和高参数整定,易于训练,并且在保证精度的前提下大大提高速度
如下图所示
 FOTS作为端到端的文本识别,使用了44.2ms; 而用某种其他方法,先检测再识别,两个步骤都分别用了四十多ms
FOTS作为端到端的文本识别,使用了44.2ms; 而用某种其他方法,先检测再识别,两个步骤都分别用了四十多ms
TextSnake(【2018ECCV】 TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes)

对于一般的文本检测,往往用一个矩形框框出内容,而TextSnake采用弯曲的凸N边形框出内容并复原为矩形,这样使得文本检测更加有效
网络结构

ContourNet(【2020 CVPR】ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection)
文章设计了文本水平与竖直方向的轮廓检测方法,对尺度(形状)变化大的文本检测任务提高了精确度
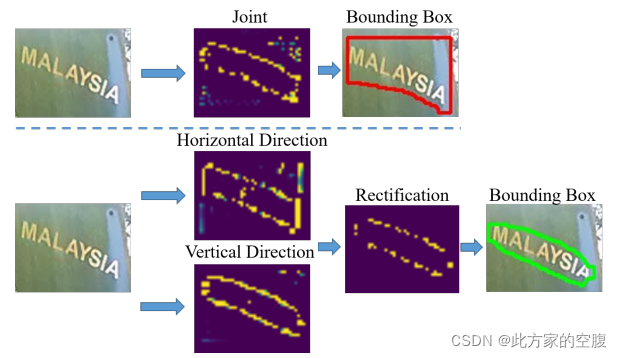
上半部分是用简单BoundingBox做的检测
下半部分用水平与竖直两方向进行检测并融合,也即文章目的
ABCNet(【2020 CVPR Oral】ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network)
Adaptive-Bezier Curve Network
主要部分是通过参数化的贝塞尔曲线作为线框来检测文本,提高了检测的有效性,并且速度较快,达到了实时性的要求

如上图所示,对一个弯曲形的文字,使用Bezier曲线来对齐(所谓BezierAlign),并拉成一个平的,从而有了更好的效果